1. 基本概念
现实场景中,在海量数据下,训练一个单一的模型往往会达不到要求,或是过于拟合。
基于这样的场景下,集成学习的产生理念就非常朴素。其核心思想是训练多个模型进行预测,互相弥补单个模型的不足。
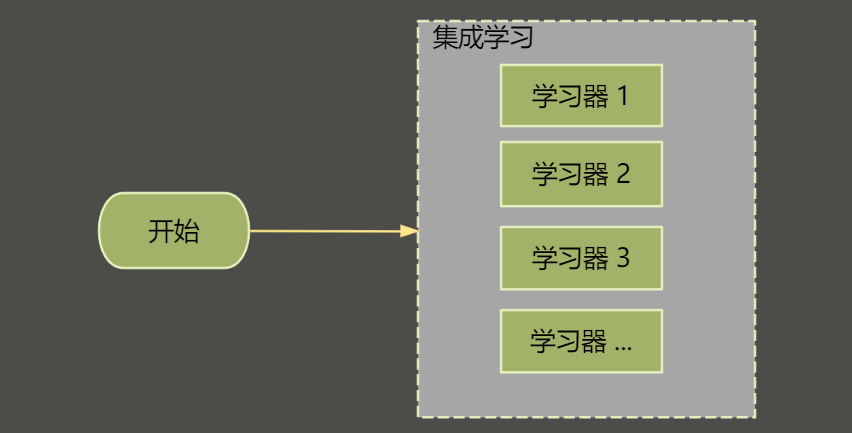
2. 集成学习的目的
简单归纳一下,使用集成学习可以尝试达到以下目的:
提高准确性:单个模型可能在某些数据集或特定任务上表现不佳,通过集成多个模型,可以减小模型误差,提高预测的准确性。
降低过拟合:集成学习可以减小单个模型过拟合的风险,因为不同模型可能会对不同的噪声敏感,通过平均多个模型的结果,可以消除一些噪声对预测的影响。
增加稳健性:集成学习可以提高模型对不同数据集和数据变化的适应性,使其更加稳健。多个模型的组合可以减少由于单个模型的不稳定性带来的影响。
利用不同模型的优势:不同的模型可能在不同的方面具有优势,集成学习可以将这些优势结合起来,构建一个更强大的模型。例如,一个模型可能在处理线性关系上表现出色,而另一个模型可能更适合捕捉非线性关系。
3. 同质与异质
我们在谈到集成学习的优点时提到,可以利用不同模型的优势。所以我们可以根据利用模型类型的数量简单分类为:
同质集成学习(Homogeneous Ensemble Learning):使用同一种基础学习器来构建集成模型。
异质集成学习(Heterogeneous Ensemble Learning):使用不同类型的基础学习器来构建集成模型。
理想化看起来,异质集成学习 更为科学、高效。然而目前异质集成学习在实际工作中的应用相对较少,因为过于复杂,使用起来相对困难。
目前同质集成学习方法通常更容易理解、实现和调优,并且在许多常见的任务中已经表现出了出色的性能。所以,接下来将聚焦于同质集成学习。
4. Bagging与Boosting
如同基本概念一样朴素,集成学习也可根据串行和并行的训练方式分为两大类Bagging(袋装法/并行)、Boosting(提升法/ 串行)。
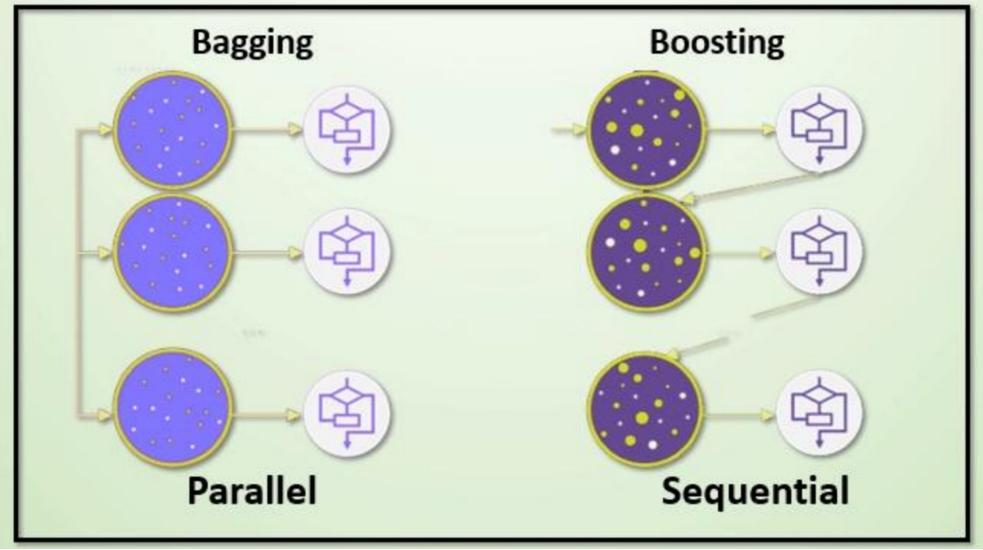
4.1 Bagging / 袋装思想
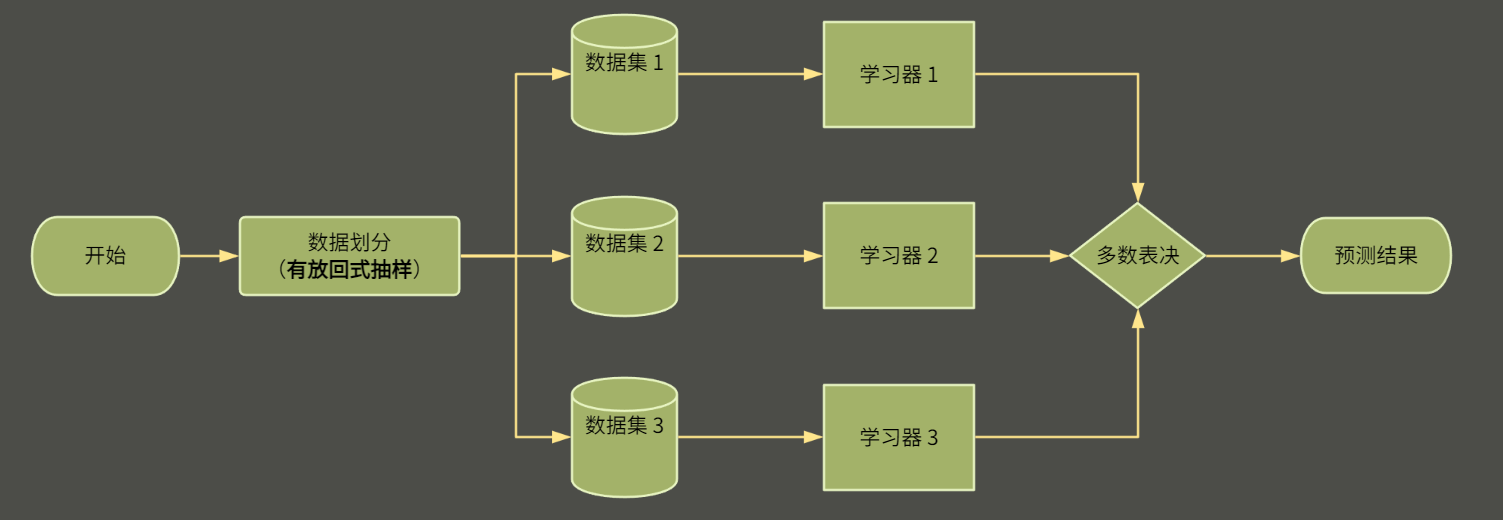
袋装法(Bootstrap Aggregating,简称Bagging)构建流程如上图:
数据采样:通过对原始数据集进行有放回抽样,有放回式 抽样划分创建多个不同的训练子集
模型训练:在每个子集上训练一个基学习器。
结果合并:在进行预测时,对于分类问题,通常采用简单投票的方式,即统计每个类别被各个基学习器预测的次数,选择得票最多的类别作为最终的预测结果
其中有放回抽样划分是指在抽样过程中,每次抽取一个样本后,将其放回总体中,然后再进行下一次抽样,具体作用我们将放到对后续bagging更具体的实现中分析。
代表性实现
随机森林(Random Forest):通过构建多个决策树并对它们的预测结果进行平均或投票来提高性能。
4.2 Boosting / 提升法
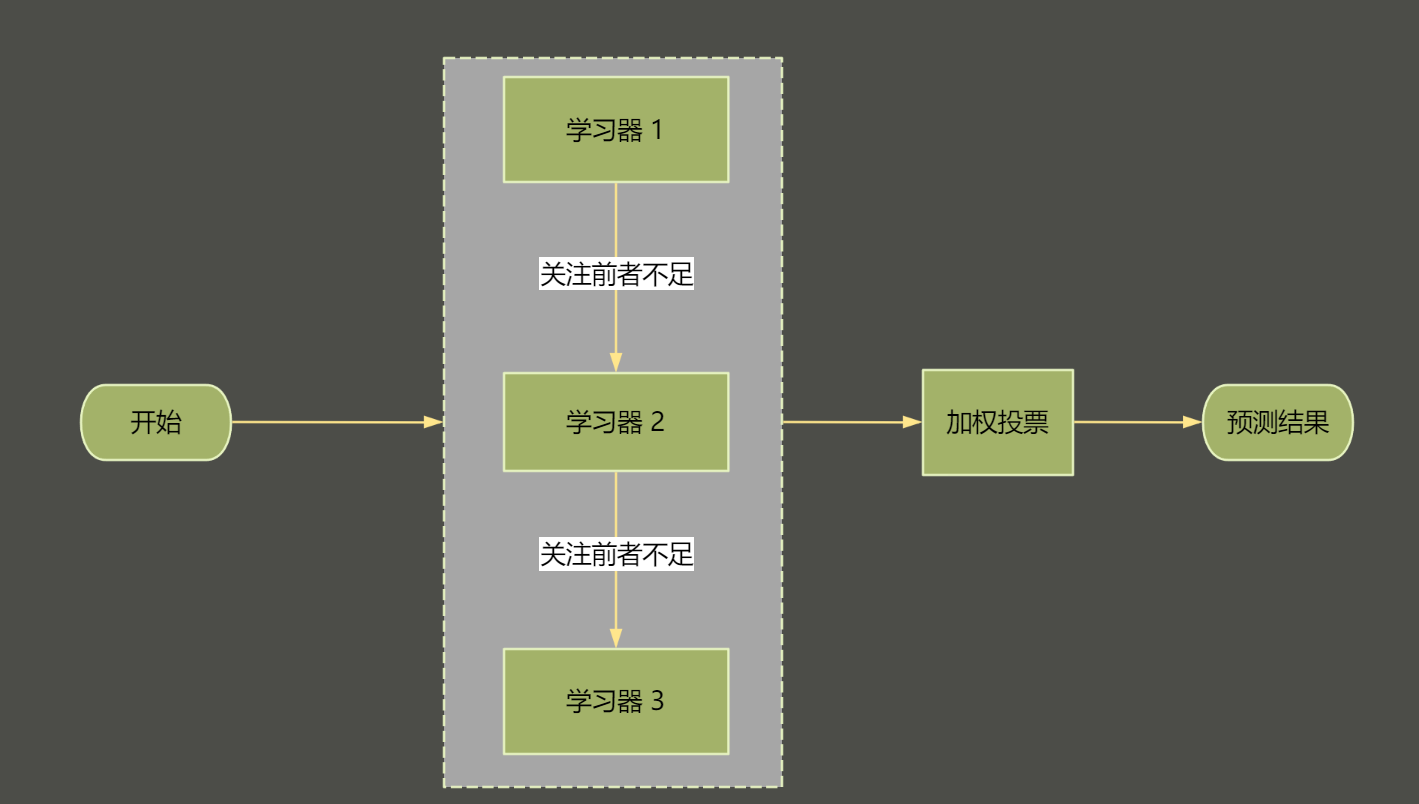
提升法(Boosting)构建程如上图:
加权数据集:每次训练时根据前一个模型的错误率调整数据权重,错误率高的数据点在后续模型中占更大权重。
顺序训练:模型按顺序逐步训练,每个模型都试图纠正前一个模型的错误。
结果合并:根据每个模型的权重对预测结果进行加权平均或加权投票。
代表性实现
AdaBoost:通过调整每个训练实例的权重来逐步构建一系列弱分类器。
梯度提升决策树(Gradient Boosting Decision Trees, GBDT):通过构建一系列决策树,每个树都试图纠正前一个模型的残差。
4.2 Bagging 与 Boosting 对比
到此为止,我们已经了解到了集成学习的概念,后续的文章中我们将更进一步了解代表性实现以及在实际应用中还需要考虑的问题。