1. 基本概念
随机森林(Random Forest)由 Leo Breiman 和 Adele Cutler 提出是一种集成学习方法,属于 Bagging 方法的一种代表性实现。主要用于分类和回归任务。它通过构建多个决策树并将其结果结合起来,能显著提高模型的准确性和鲁棒性。
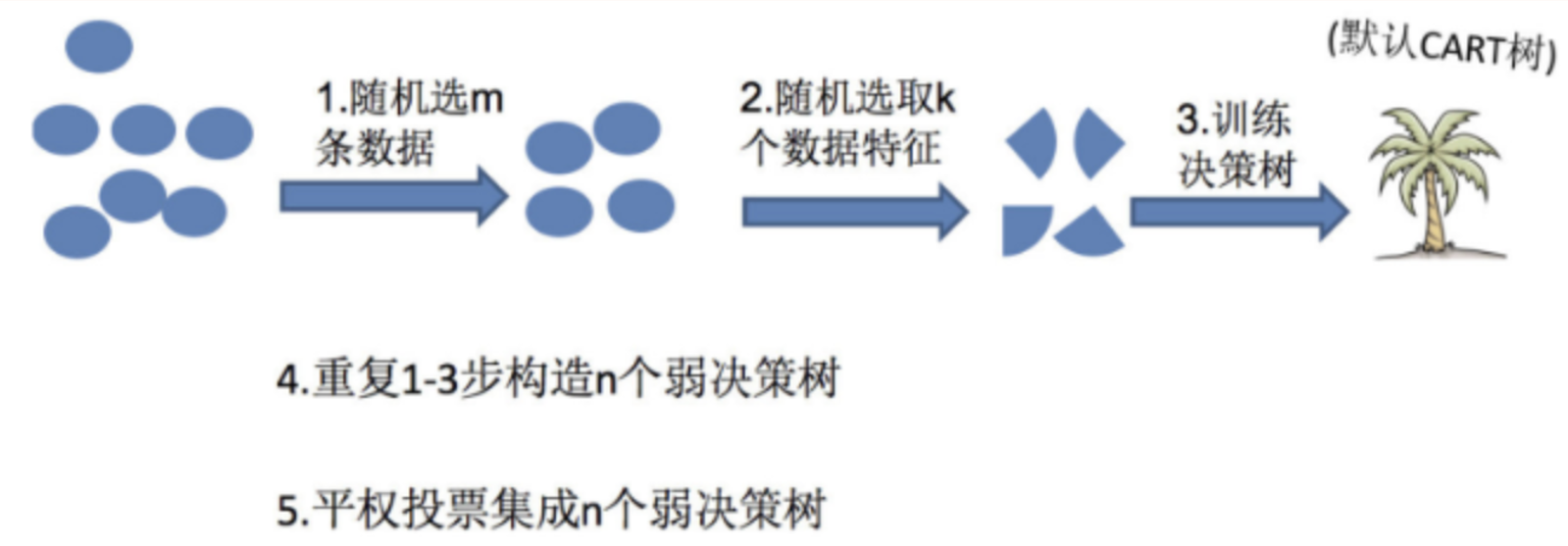
算法步骤如上图:
数据集重采样:从原始训练数据集中随机有放回地抽取样本,形成多个子数据集,每个子数据集用于训练一棵决策树。
训练决策树:对于每个子数据集,构建一棵决策树。在构建过程中,每个节点分裂时随机选择部分特征进行考虑,从中选择最佳特征进行分裂。
组合模型:将所有决策树的结果组合起来。对于分类任务,通过多数投票决定最终分类结果;对于回归任务,通过平均所有树的预测结果得到最终预测值。
1.1 有放回的取样
有放回地随机抽取样本是理解该算法的特点,其意义是指在抽样过程中,每次抽取一个样本后,将其放回总体中,然后再进行下一次抽样。
有放回地随机抽取样本策略可以和其它策略做下对比:
与全量数据相比,简化了计算与分析,且如果样本一致,训练出的树模型也将一致
与分批无交集数据相比,如果每棵树的训练样本都是不同的,都是没有交集的,这样每棵树都是“有偏的”,也就是说每棵树训练出来都是有很大的差异的,最终投票也将难以进行
所以随机有放回抽取样本,目的是达成既有交集也有差异分批数据,简化计算分析,同时更容易发挥投票表决效果。
1.2 投票逻辑
在随机森林中,构建了一个包含多棵决策树的随机森林模型,当有新的数据需要进行预测时,会将该数据输入到随机森林中的每一棵决策树中。其投票逻辑如下:
对于分类问题:
一棵决策树都会根据自身学到的规则和特征对输入数据进行分类,并给出一个类别预测结果。
随机森林会综合所有决策树的预测结果来进行投票决定最终的类别归属。常见的投票方式是少数服从多数,即统计各个类别被预测的次数,选择被预测次数最多的类别作为随机森林的最终预测类别。
例如,随机森林中有100棵决策树,输入一条需要预测的数据后,有70棵决策树预测结果是类别 A,30 棵决策树预测结果是类别 B,那么最终随机森林的预测结果就是类别 A。
对于回归问题:每一棵决策树会给出一个数值预测结果(例如连续的数值)。随机森林的最终预测结果通常是取所有决策树预测值的平均值作为输出。
例如,100棵决策树对某个样本的预测值分别为 x_1, x_2, \cdots, x_{100},则该样本的最终预测值可以计算为 (x_1 + x_2 + \cdots + x_{100})/ 100。
2. 适用场景
1. 高维数据处理:随机森林能够处理包含大量特征的数据集,尤其适用于高维数据集,在不进行特征选择的情况下也能很好地工作。
2. 特征重要性评估:随机森林能够评估每个特征的重要性,这对于需要特征选择或解释模型的场景非常有用。
3. 非线性关系处理:随机森林能处理复杂的非线性关系,因为它结合了多个决策树的结果,每个决策树都能够捕捉不同的非线性关系。
4. 缺失值处理:随机森林能够处理数据中的缺失值,并且通过内置的缺失值处理机制,在模型训练时自动补全缺失值。
5. 分类和回归任务:随机森林在分类和回归任务中表现出色,广泛用于各种机器学习任务中。
6. 防止过拟合:由于随机森林通过对多个决策树的结果进行平均或多数投票来做出最终预测,从而有效地防止了单个决策树可能出现的过拟合问题。
2.1 应用案例
1. Netflix的推荐系统:
Netflix使用随机森林来分析用户观看历史、评分和行为,提供个性化的内容推荐,从而提高用户满意度和平台留存率。
2. Amazon的产品推荐:
Amazon利用随机森林分析用户的购买记录、浏览习惯等,通过推荐相关产品来增加销售额和用户黏性。
3. Airbnb的价格预测:
Airbnb使用随机森林模型预测房源的租金价格,通过分析地理位置、房屋特征、用户评论等因素,提供合理的定价建议。
3. 代码实现
3.1 函数说明
由于随机森林的逻辑相对简单,这里不再加以数学分析直接以python代码实现。首先,让我们熟悉一下sklearn中的常见的函数和其参数,以及工作中常见的取值。
from sklearn.ensemble import RandomForestClassifier
"""
用于分类数据
"""
rf = RandomForestClassifier(
n_estimators=100, # 树的数量
criterion='gini', # 分裂节点的标准
max_depth=None, # 树的最大深度
min_samples_split=2, # 分裂内部节点所需的最小样本数
min_samples_leaf=1, # 叶节点所需的最小样本数
max_features='auto', # 寻找最佳分割点时考虑的特征数量
bootstrap=True, # 是否进行自助采样
oob_score=False, # 是否使用袋外样本评估模型
random_state=None, # 随机种子
n_jobs=None # 并行工作的线程数量
)
from sklearn.ensemble import RandomForestRegressor
"""
用于回归数据
"""
rf = RandomForestRegressor(
n_estimators=100, # 树的数量
criterion='mse', # 分裂节点的标准
max_depth=None, # 树的最大深度
min_samples_split=2, # 分裂内部节点所需的最小样本数
min_samples_leaf=1, # 叶节点所需的最小样本数
max_features='auto', # 寻找最佳分割点时考虑的特征数量
bootstrap=True, # 是否进行自助采样
oob_score=False, # 是否使用袋外样本评估模型
random_state=None, # 随机种子
n_jobs=None # 并行工作的线程数量
)
在实际场景中常用参数及取值如下:
1. `n_estimators`(树的数量)
- 重要性:高
- 常见取值:100到500
- 说明:树的数量越多,模型越稳定,但计算成本也更高。100到500棵树通常能够提供良好的性能和平衡计算成本。
2. `max_depth`(最大深度)
- 重要性:高
- 常见取值:10到None
- 说明:限制树的深度可以防止过拟合。具体取值根据数据集和问题类型而定,通常通过交叉验证来选择最佳深度。
3. `min_samples_split`(分裂所需的最小样本数)
- 重要性:中
- 常见取值:2到10
- 说明:较高的值可以防止过拟合,使模型更简单、更稳健。
4. `min_samples_leaf`(叶节点所需的最小样本数)
- 重要性:中
- 常见取值:1到5
- 说明:设置较高的值可以避免树变得过于复杂,有助于提高模型的泛化能力。
5. `max_features`(寻找最佳分割点时考虑的特征数量)
- 重要性:高
- 常见取值:'auto'(分类问题中自动使用'sqrt'),'sqrt'(回归问题中也常用)
- 说明:控制每个节点考虑的特征数量可以增加树之间的多样性,提高模型的性能。
6. `bootstrap`(是否进行自助采样)
- 重要性:中
- 常见取值:True
- 说明:启用自助采样可以让每棵树对不同的样本子集进行训练,提高模型的泛化能力。
7. `random_state`(随机种子)
- 重要性:中
- 常见取值:整数值(如42)
- 说明:设置相同随机种子可以保证结果的可重复性。
8. `n_jobs`(并行工作的线程数量)
- 重要性:高
- 常见取值:-1(使用所有可用的CPU)
- 说明:并行化计算可以显著加快模型训练速度。
3.2 python实现
我们将在 sklearn.datasets 的乳腺癌数据集上进行训练和评估。
并建立一个单一决策树、直接定义随机森林决策树与网格交叉验证的随机森林决策树,训练模型,并进行对比。
""" some exercises on ensemble learning"""
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import GridSearchCV, train_test_split
from sklearn.metrics import classification_report, confusion_matrix
from sklearn.tree import DecisionTreeClassifier
def random_tree():
"""a function to create a random forest classifier and compare it with a single decision tree classifier"""
# Load the iris dataset
data = load_breast_cancer()
x = data.data
y = data.target
# split the dataset into training and testing sets
x_train, x_test, y_train, y_test = train_test_split(
x, y, test_size=0.2, random_state=99
)
# create a single desicion tree
dtc = DecisionTreeClassifier(random_state=99)
dtc.fit(x_train, y_train)
dtc_y_predictions = dtc.predict(x_test)
dtc_accuracy = dtc.score(x_test, y_test)
# create a random forest classifier
rfc = RandomForestClassifier(n_estimators=10, random_state=99)
# train the classifier
rfc.fit(x_train, y_train)
# make predictions
rfc_y_predictions = rfc.predict(x_test)
# evaluate the classifier
rfc_accuracy = rfc.score(x_test, y_test)
rfc_improvement = RandomForestClassifier()
param = {
"n_estimators": [10, 20, 30, 40, 50],
"max_depth": [2, 4, 6, 8, 10, 12],
"random_state": [99],
}
grid_search = GridSearchCV(rfc_improvement, param, cv=5)
grid_search.fit(x_train, y_train)
gs_y_predictions = grid_search.predict(x_test)
gs_accuracy = grid_search.score(x_test, y_test)
# evaluate the accuracy of the classifiers
print("################ score ###################")
print(f" 1 singnle decision tree = {dtc_accuracy} ")
print(f" 2 random forest = {rfc_accuracy} ")
print(f" 3 random forest graid = {gs_accuracy} ")
print(" ")
# report the classification
print("################ report ###################")
print(" 1 singinle decision tree is follow:")
print(classification_report(y_test, dtc_y_predictions))
print(" 2 random forest classifier is follow: ")
print(classification_report(y_test, rfc_y_predictions))
print(" 3 random forest graid classifier is follow: ")
print(classification_report(y_test, gs_y_predictions))
print(" ")
# report the confusion matries
print("################ confusion matries ###################")
print(" 1 single decision tree is follow: ")
print(confusion_matrix(y_test, dtc_y_predictions))
print(" 2 random forest classifier is follow: ")
print(confusion_matrix(y_test, rfc_y_predictions))
print(" 3 random forest graid classifier is follow: ")
print(confusion_matrix(y_test, gs_y_predictions))
print(" ")
if __name__ == "__main__":
random_tree()
输出如下:
################ score ###################
1 singnle decision tree = 0.9122807017543859
2 random forest = 0.9473684210526315
3 random forest graid = 0.9736842105263158
################ report ###################
1 singinle decision tree is follow:
precision recall f1-score support
0 0.89 0.84 0.86 38
1 0.92 0.95 0.94 76
accuracy 0.91 114
macro avg 0.91 0.89 0.90 114
weighted avg 0.91 0.91 0.91 114
2 random forest classifier is follow:
precision recall f1-score support
0 0.94 0.89 0.92 38
1 0.95 0.97 0.96 76
accuracy 0.95 114
macro avg 0.95 0.93 0.94 114
weighted avg 0.95 0.95 0.95 114
3 random forest graid classifier is follow:
precision recall f1-score support
0 1.00 0.92 0.96 38
1 0.96 1.00 0.98 76
accuracy 0.97 114
macro avg 0.98 0.96 0.97 114
weighted avg 0.97 0.97 0.97 114
################ confusion matries ###################
1 single decision tree is follow:
[[32 6]
[ 4 72]]
2 random forest classifier is follow:
[[34 4]
[ 2 74]]
3 random forest graid classifier is follow:
[[35 3]
[ 0 76]]
################ fit time ###################
1 single decision tree = 0.0064754486083984375
2 random forest = 0.015347719192504883
3 random forest graid = 5.862706899642944可见,使用单决策树、直接定义随机森林、网格筛选随机森林,训练出的模型是逐渐加强的。
当然,与此同时,消耗的时间与算力同样也在逐渐加剧,其中网格筛选呈现了巨额时间增长。
接下来,我们将继续探索Boosting算法。